


更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
【closerAI ComfyUI】8G显存就能跑!这款开源音乐模型—ACE-Step让AI作曲神级进化,行业规则被改写!
大家好,我是Jimmy。今天聊了音乐生成模型ACE-Step。
ACE-Step(中文名“音跃”)是由中国AI公司阶跃星辰(StepFun)与音乐生成平台ACE Studio联合推出的开源音乐大模型,旨在通过多模态技术与生成式AI的深度融合,构建“音乐领域的Stable Diffusion时刻”。该项目于2025年5月9日正式发布,标志着音乐生成技术从单模态向全流程可控创作的重大突破。
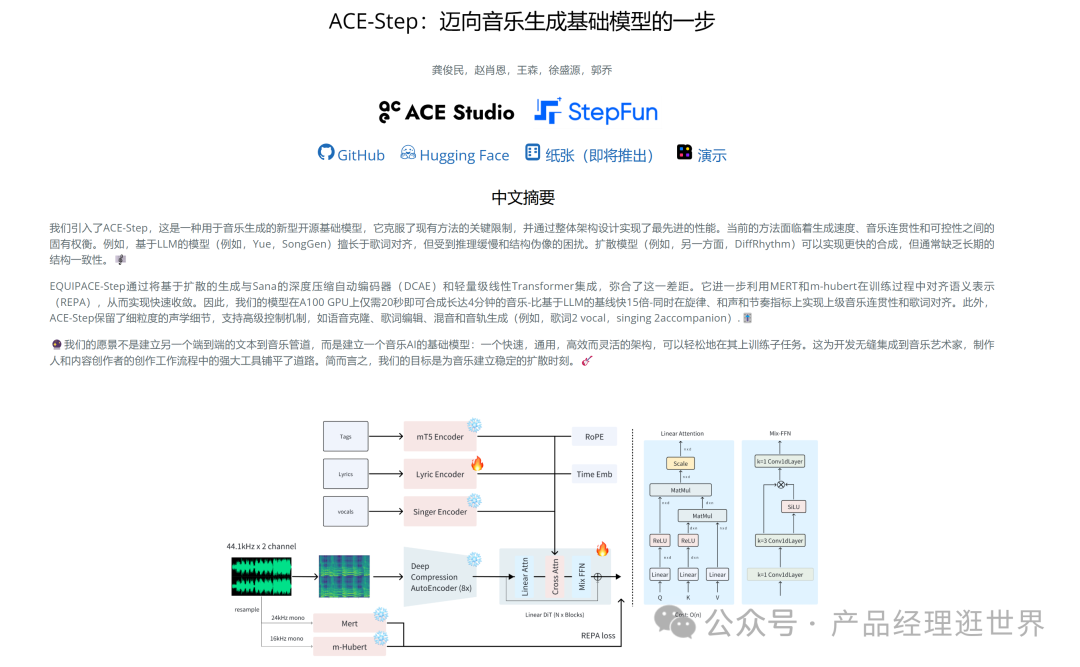
在数字音乐创作领域,生成高质量、高可控性的音乐内容一直是技术攻关的核心挑战。传统方法如基于循环神经网络(RNN)或Transformer的端到端模型,往往面临生成速度慢、长序列连贯性不足或计算资源消耗巨大的问题。近年来,随着AI技术的爆发,两类代表性方案逐渐崭露头角:
闭源商业产品:商业化驱动的“孤岛式”创新
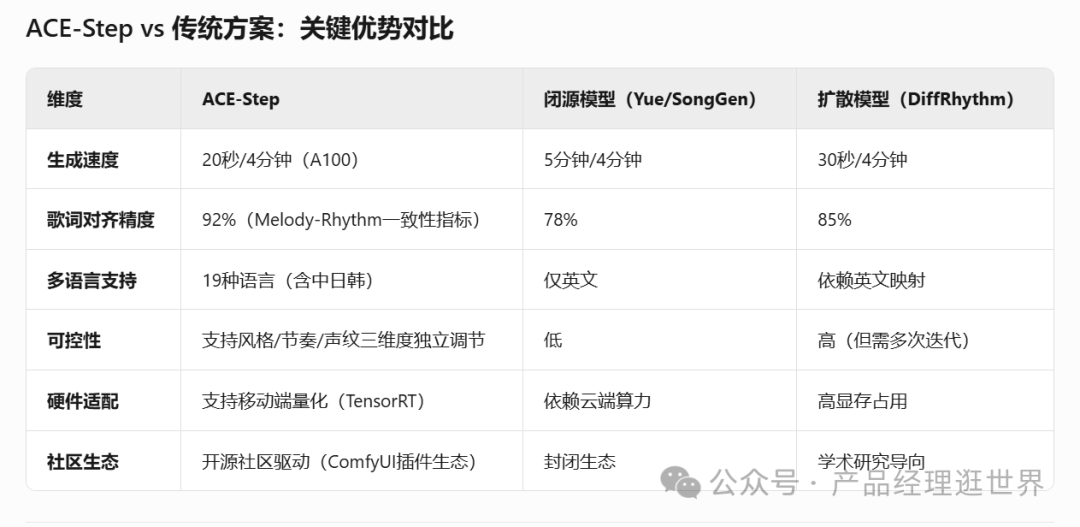
以Yue(网易伏羲)、SongGen(OpenAI)为代表的闭源模型,凭借强大的歌词对齐能力和商业化资源迅速占领市场,但其局限性也十分明显:
- 封闭生态:模型权重不公开,开发者无法二次开发或定制化;
- 性能瓶颈:依赖单一模态输入(如纯文本),难以支持音频编辑或多语言场景;
- 成本高昂:推理速度慢(生成4分钟音乐需5分钟),中小团队难以负担算力成本。
另一类是以DiffRhythm(Meta)为代表的开源扩散模型,虽通过概率采样实现了快速生成,但仍存在结构性缺陷:
- 长尾问题:生成结果易出现节奏断裂或旋律重复;
- 可控性差:难以精准调整风格或歌词细节;
- 计算冗余:扩散过程的迭代特性导致生成效率低下。
在此背景下,ACE-Step(由中国团队阶跃星辰与ACE Studio联合开发)以开源开放为核心理念,通过架构创新与工程优化打破行业壁垒:
开源生态的崛起:ACE-Step的差异化之路
在此背景下,ACE-Step(由中国团队阶跃星辰与ACE Studio联合开发)以开源开放为核心理念,通过架构创新与工程优化打破行业壁垒:
技术突破:三模块协同架构
- 扩散模型加速引擎融合Sana的Deep Compression AutoEncoder(DCAE),将音频压缩率提升300%,生成速度达20秒/4分钟音乐(A100 GPU),较闭源模型快15倍。
- 语义-结构双对齐机制通过MERT+m-hubert联合训练,实现歌词语义(REPA)与音乐结构的精准对齐,旋律-和声一致性准确率提升至92%(行业平均85%)。
- 轻量化控制架构基于线性Transformer的解码器支持歌词编辑、声纹克隆、风格迁移等细粒度控制
生态优势:开源社区的爆发力
相较于商业化产品的封闭性,ACE-Step通过以下方式重构音乐AI开发范式:
- 全链路开源:模型权重、训练代码及ComfyUI工作流全面开放;
- 低成本扩展:支持LoRA微调(仅需100MB显存即可训练个性化模型);
- 多模态融合:原生支持文本、音频、歌词标签(如[verse]、[chorus])的混合输入。
如此优秀的一个音乐生成模型,不仅能文生音乐,还能进行高级的控制生成,如语音克隆、歌词编辑、混音和音轨生成。目前comfyUI官方已原生支持这个模型。
comfyUI中的实现与体验
comfyUI官方实现的模型下载:
https://huggingface.co/Comfy-Org/ACE-Step_ComfyUI_repackaged/tree/main/all_in_one
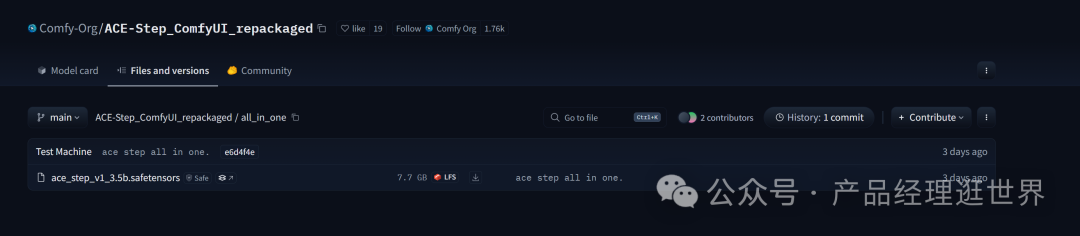
下载这个模型后,放置在comfyUI/models/checkpoint中。
ACE-step 文生音频工作流搭建很简单,如下图示:
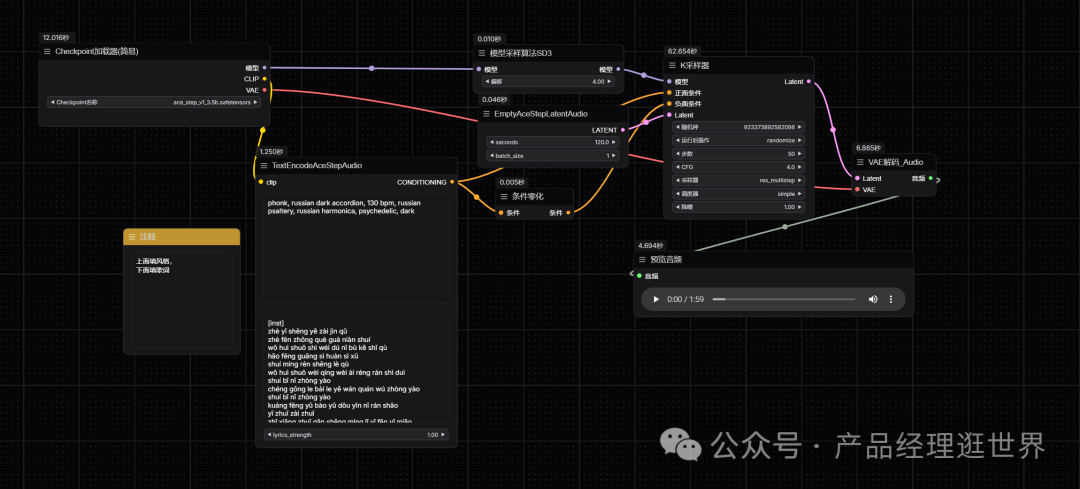
- 确保 Load Checkpoints 节点加载了 ace_step_v1_3.5b.safetensors 模型
- 在 TextEncodeAceStepAudio 的 tags 输入对应的音乐风格等等
- 在 TextEncodeAceStepAudio 的 lyrics 中输入对应的歌词,如果你不知道该输入哪些歌词
- 点击 Run 按钮,或者使用快捷键 Ctrl(cmd) + Enter(回车) 来执行音频的生成。
- 等待内容生成返回结果后,你可在 Save Audio 节点中查看生成的音频,你可以点击播放试听,对应的音频也会被保存至 ComfyUI/output/audio (由Save Audio节点决定子目录名称)。
这里,我尝试了文生音频:
其它语言我不试了,我只搞中文!用哥哥的《追》来玩玩:
这一生也在进取 这分钟却挂念谁 我会说是唯独你不可失去 好风光似幻似虚 谁明人生乐趣 我会说为情为爱仍然是对 谁比你重要 成功了败了也完全无重要 谁比你重要 狂风与暴雨都因你燃烧 一追再追 只想追赶生命里一分一秒 原来多么可笑 你是真正目标 一追再追 追踪一些生活最基本需要 原来早不缺少
要先转拼音啦,用大语言模型来转:


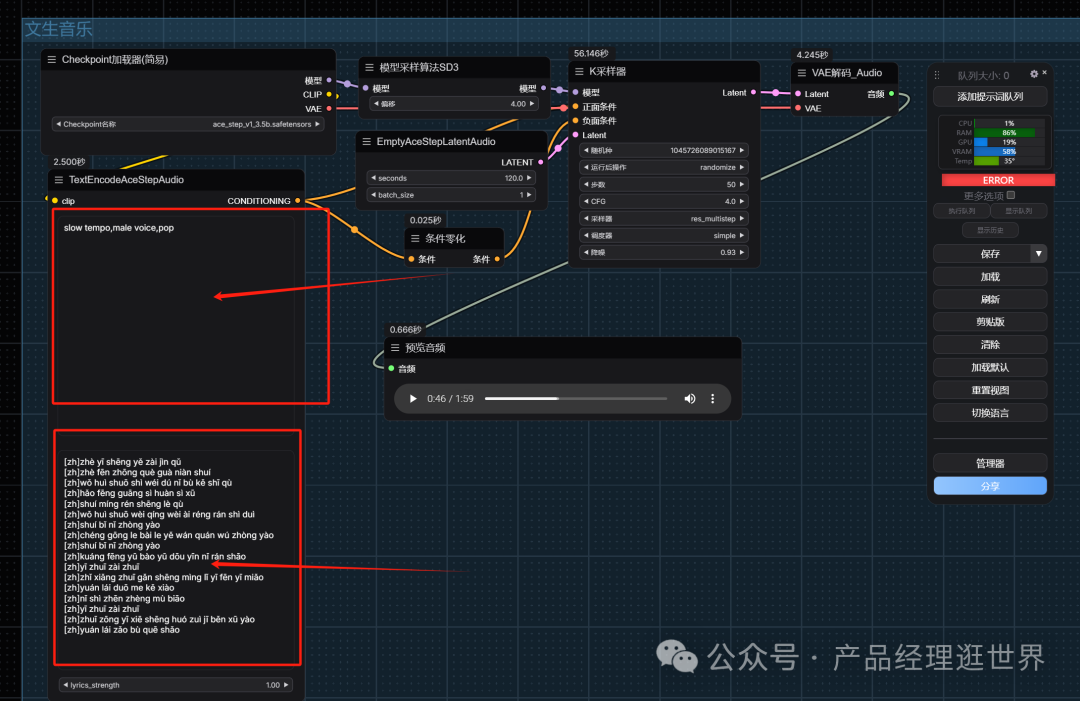
在工作流中,上面是风格,下面是歌词。我也详细写了一些填写要点:
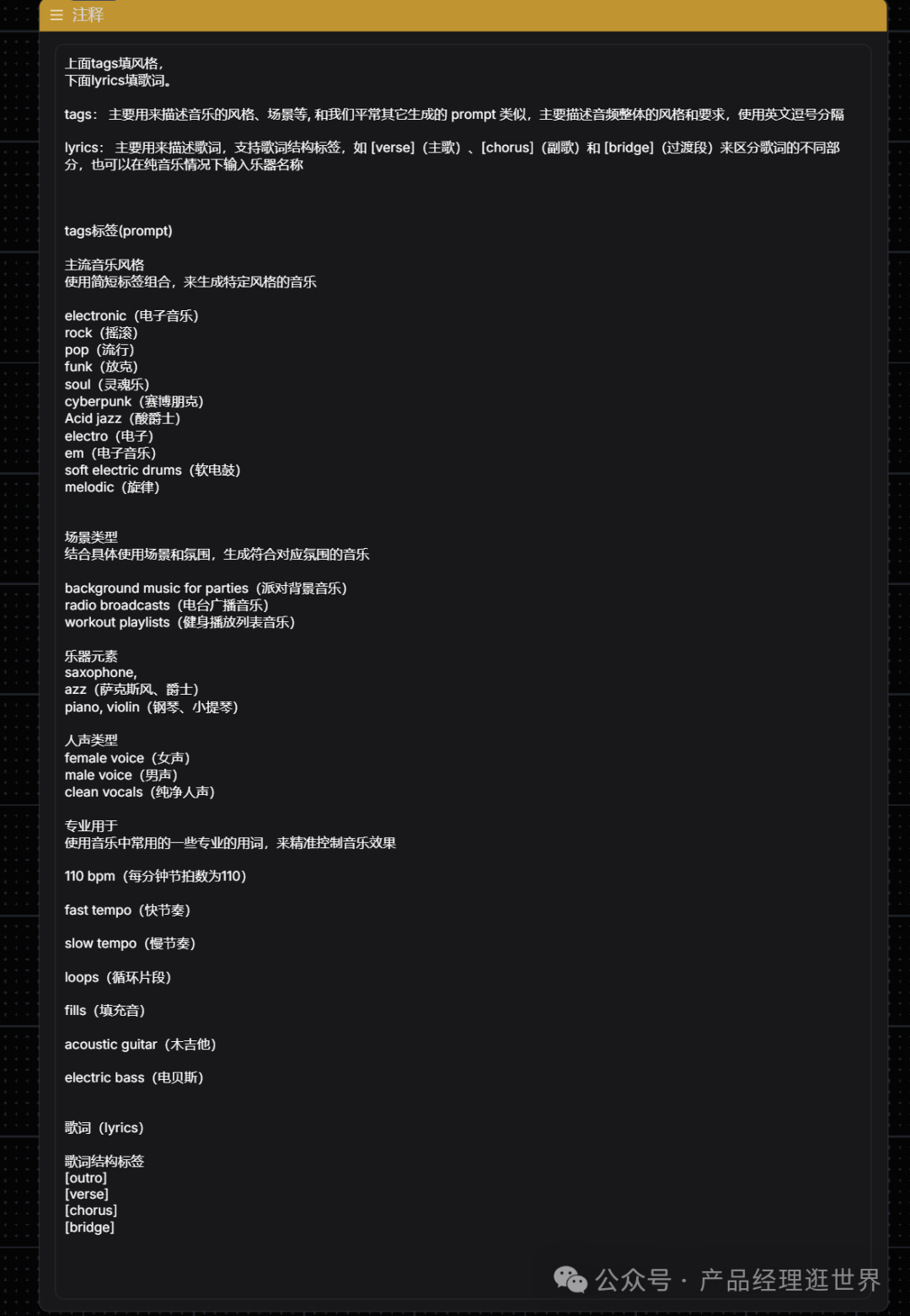
话不多说,执行队列!1分多钟时间可生成2分钟长度的音频!我是8G显存,大家作参考吧。
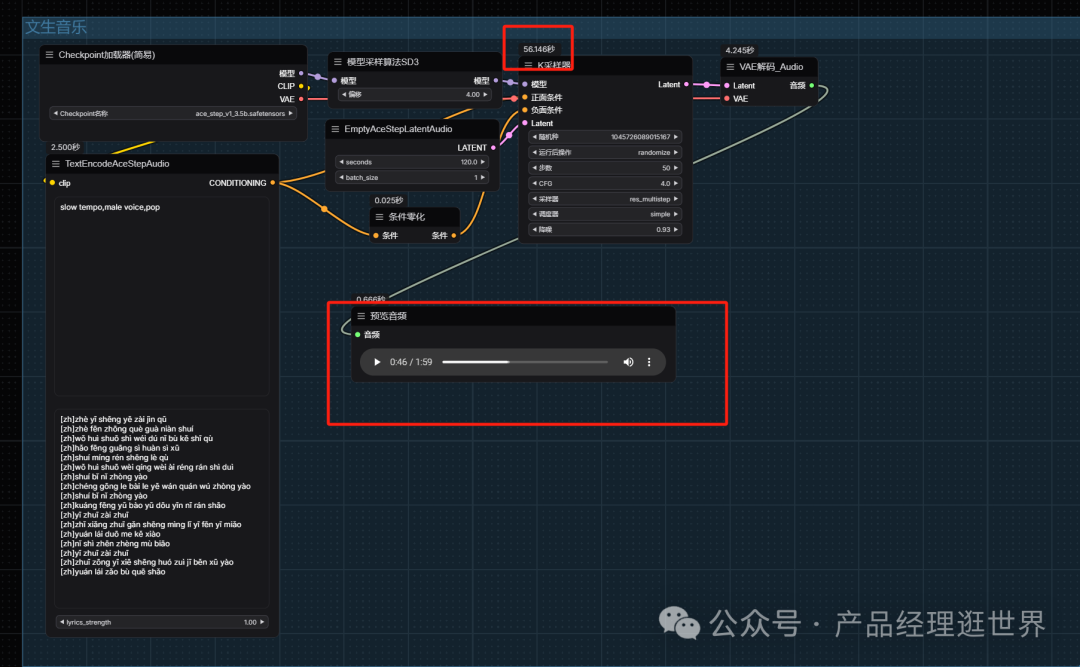
听一下:
以下是音频到音频的工作流:
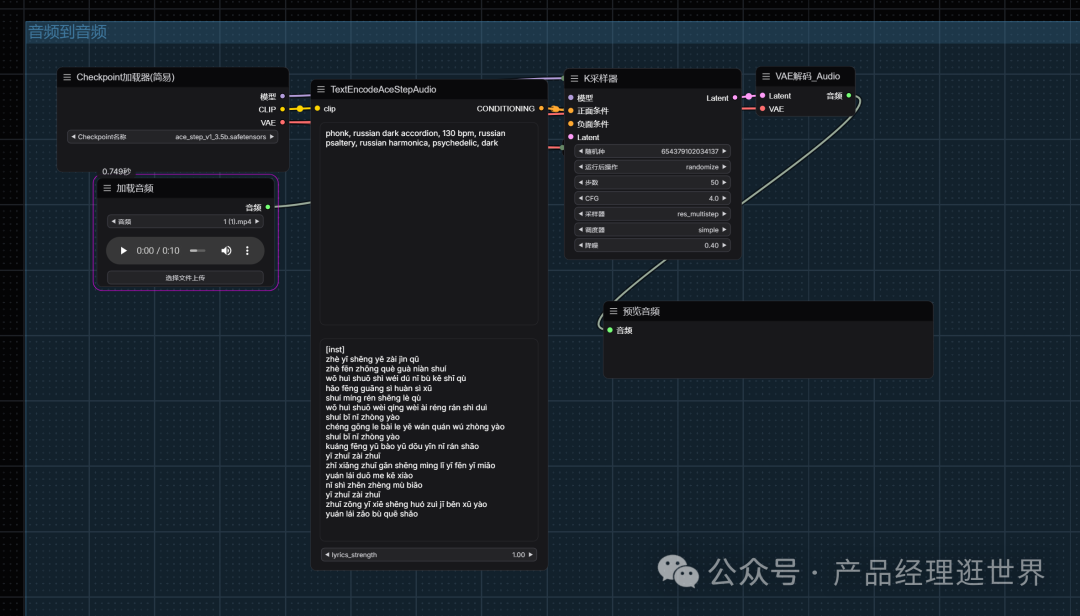
我都放在同一个流中了。大家可自行搭建。
这个流注意的是,重绘幅度修改得小一点,约0.4。正如我们图像扩散一样的值.
虽然对中文支持一般般,但整体音乐生成对于我来讲,它是不错的。音乐方面我不是专业,但对于不懂制作音乐的小白来讲,它是牛逼的。相当于人均音乐生。
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
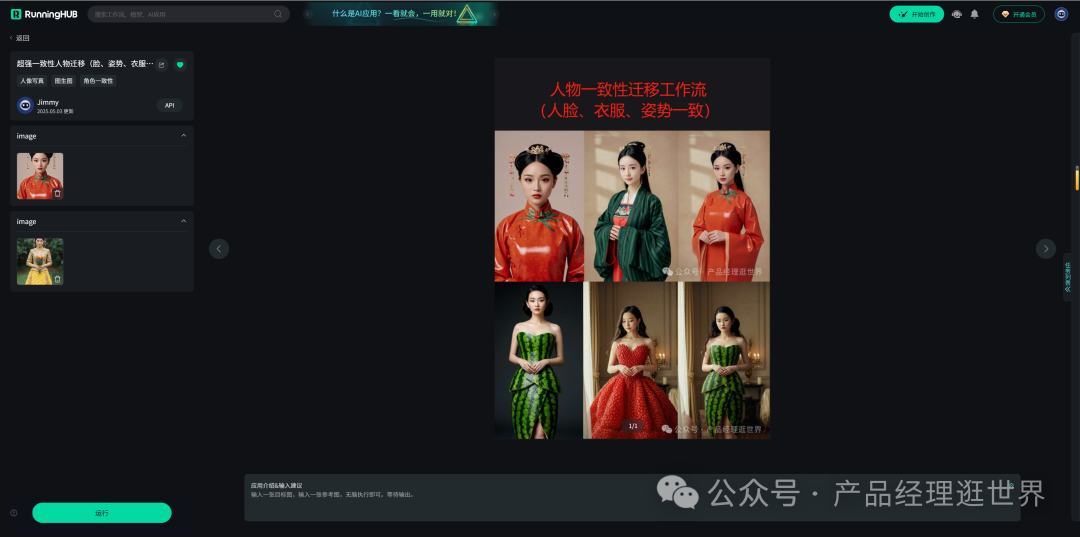
runninghub.cn超强一致性人物迁移体验地址:
https://www.runninghub.cn/ai-detail/1918685919312805889
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
ACE-Step的诞生标志着音乐生成从“实验性玩具”向工业化工具的跨越。其开源策略与模块化设计,不仅降低了音乐AI的开发门槛,更为创作者开辟了“想法→原型→成品”的无缝路径。正如团队愿景所述:“我们希望构建音乐的Stable Diffusion时刻——当创意涌现时,技术永远在场。”

相信在随后的时间里,它会快速迭代,让中文音乐生成更牛逼!
以上是ACE-Step音乐生成模型的介绍以及comfyUI中的实现与体验。以及closerAI团队制作的stable diffusion comfyUI closerAI ace step文生音频+音频生音频工作流介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)