


更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】kontext姿势控制实验!深挖kontext姿势控制编辑的可能性!双图kontext预设姿势克隆与flux一致性人物姿势对比!
大家好,我是Jimmy。这几天有点事没更新。
最近在研究关于flux kontext精准姿势控制编辑的可能性。
没错,关于FLUX生态下实现姿势控制,此前我们也实现过,那个FLUX万物迁移下实现的人物迁移!效果相当不错:
【closerAI ComfyUI】高效精准!nunchaku增强版人物姿势迁移,人脸、姿势、服装一次性迁移!控制必备!收藏学习
【closerAI ComfyUI】惊艳!人物姿势迁移+视频秀,赋能电商拍摄、模特上装、个人写人、微短剧分镜设计等应用场景,赞!
这是此前的工作流:
这是FLUX万物迁移下人物一致性姿势迁移的效果:工作流在我们网站找

我的一个小短片也是通过这工作流实现人物替换实现的,之前也文章介绍过实现方法:
【closerAI ComfyUI】人人都是导演!人物一致性迁移工作流在微短剧制作中的实战!简单易上手,1小时生产一个短剧!爽!
所以,这个方法是可行性非常高且成熟的方法。
因为kontext dev的能力是ID一致性的图像编辑嘛,所以想探索它关于姿势控制编辑的实现。
前几天也介绍过通过白模3D的形式实现单图编辑下人物生成,但这个方法是随机生成的人物,与我们想要的人物有巨大偏差。
其实在此前也有探索过kontext姿势控制:
【closerAI ComfyUI】flux kontext dev提示词指南,同时探索controlnet控制一起生成的可行性
当时把controlnet当成条件串联起来时,会报错,在后通过条件平均来实现姿势引导,效果还是有的。
以下加入controlnet一起引导:
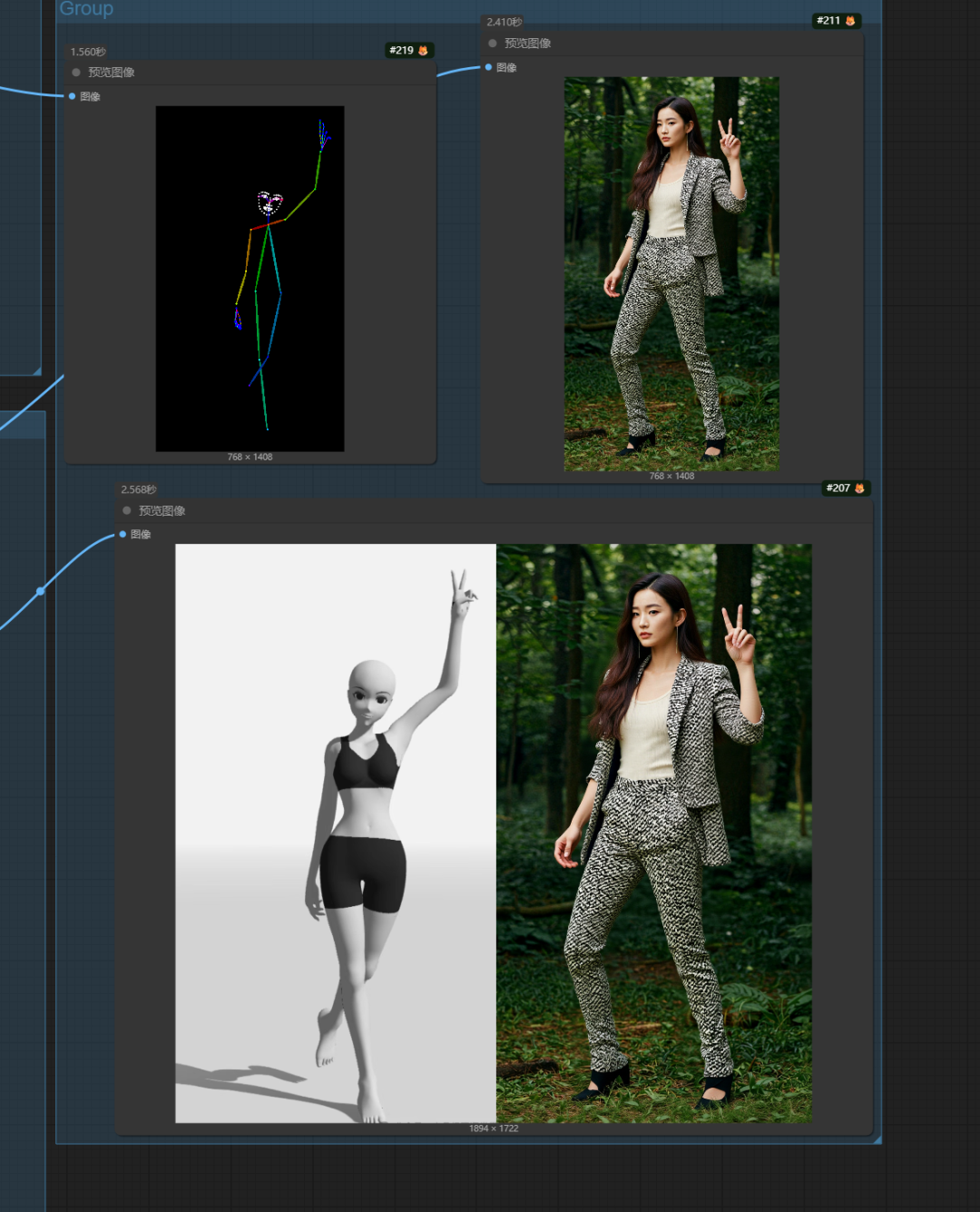

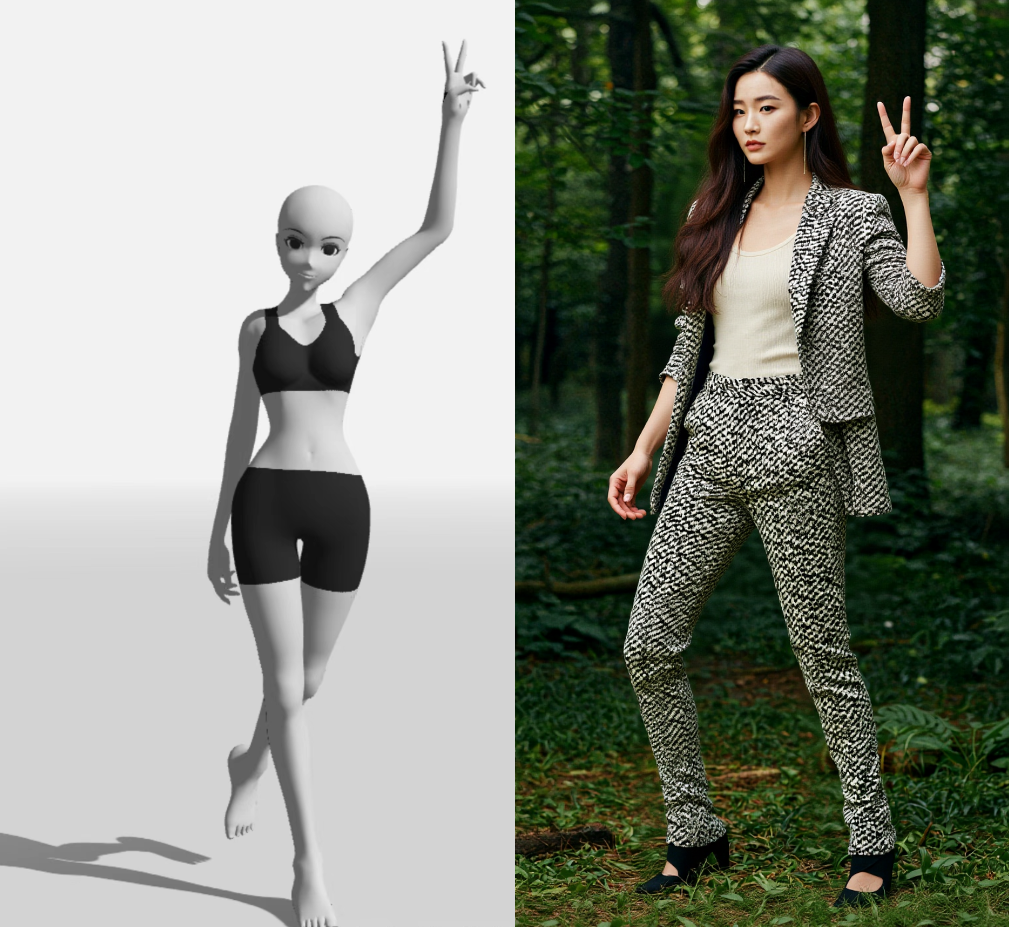
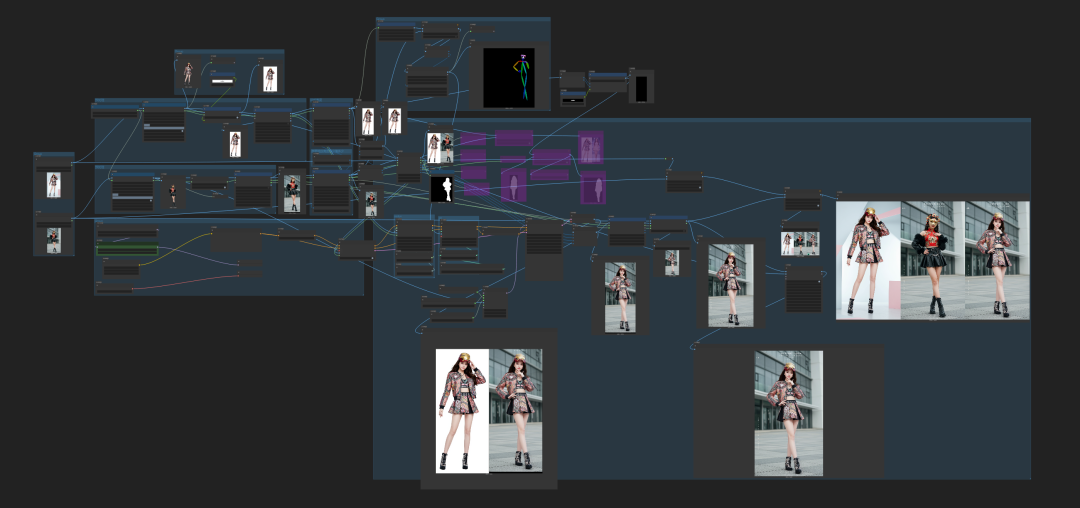
下面我尝试利用kontext预设系统的指令方式(官方提供的是单图的,参考这种方式形成双图预设指令),将两张图,一张是姿势参考,让LLM详细描述姿势动作形成自然语言提示词,然后第二张是目标图,让LLM将姿势动作形成姿势编辑指令提示词!尝试以更为详细的文本指令加强姿势控制。
是的,指令越详细,kontext将越遵循。提示词是重点。
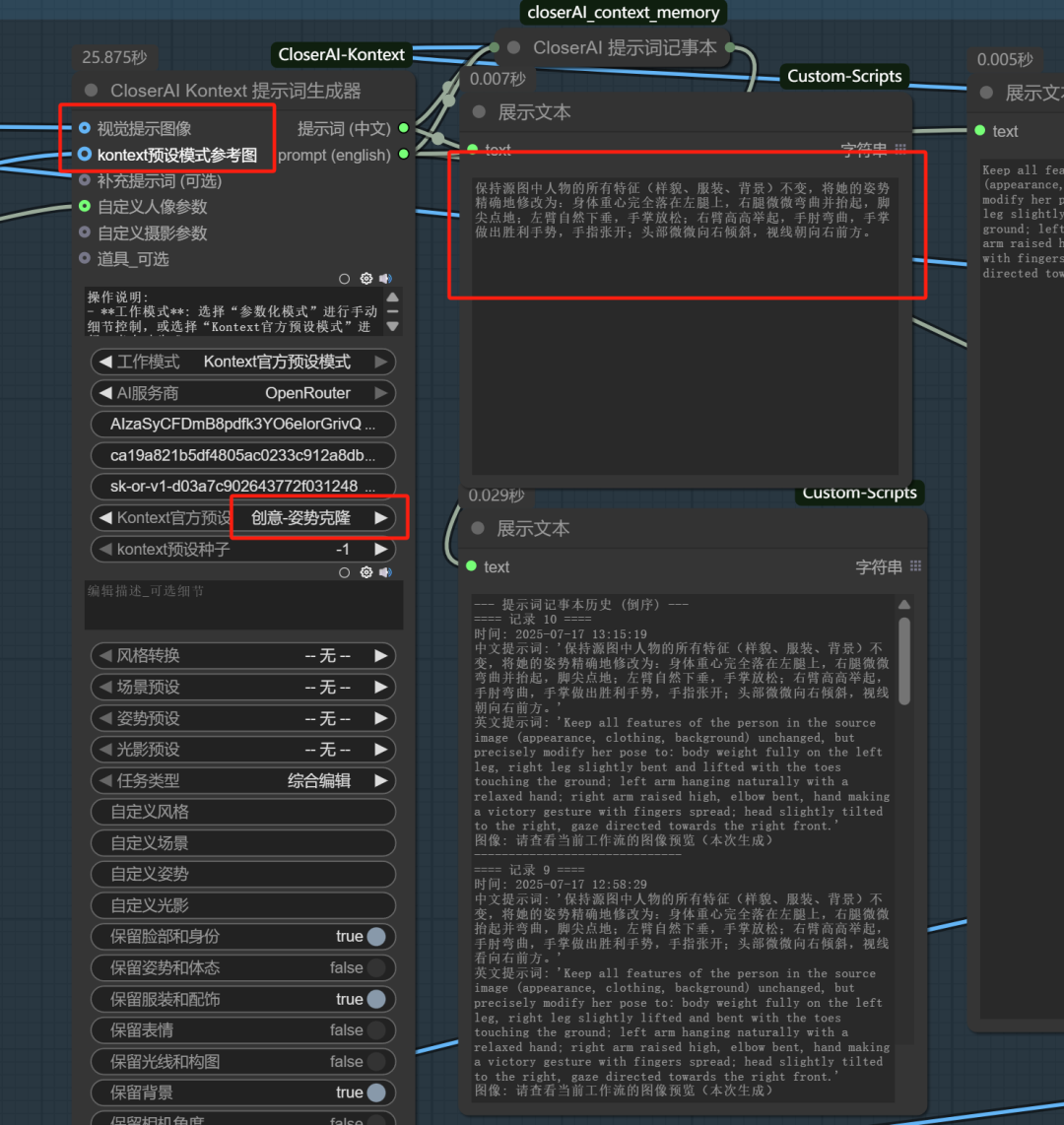
第一步就是优化我们的提示词生成器,加入双图参考,同时预设一个LLM指令:
可将姿势参考图接入至视觉提示图像,将目标图接入“kontext”预设模式参考图中。在“kontext官方预设“中选择”创意-姿势克隆“,然后让LLM进行姿势描述,等待生成提示词即可。
因为是双图编辑,所以使用kontext双图编辑工作流:
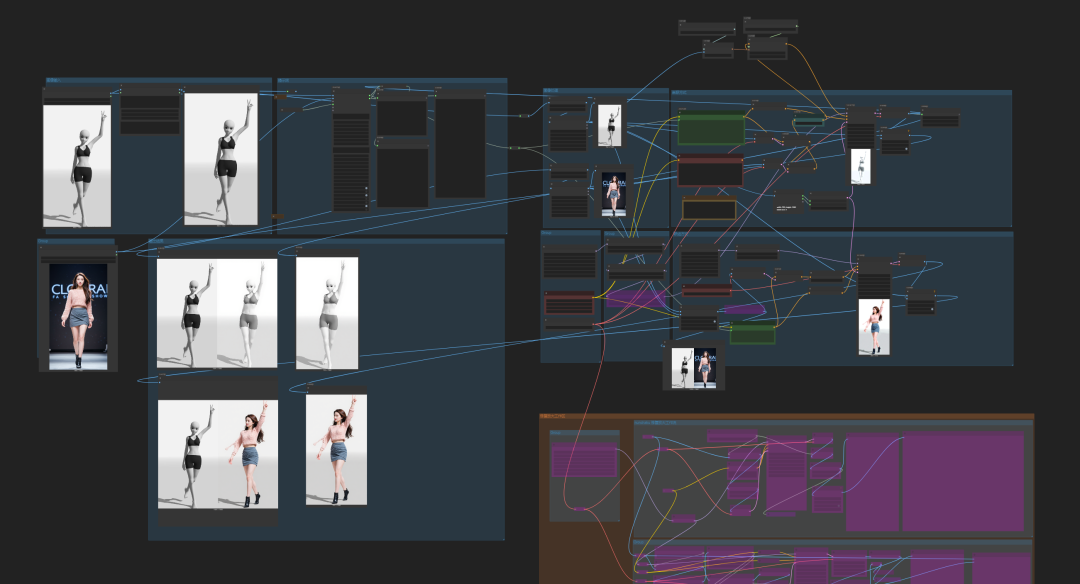
执行下工作流:


以下是第三次抽卡时的效果。

换了个人:



测试过程中,我加入了串联方式和联结的方式。发现联结方式,在成功率上比串联方式的要高,但也不完全说是哪个更好,最好的办法就是两种方式接入生成结果然后选择最优的。
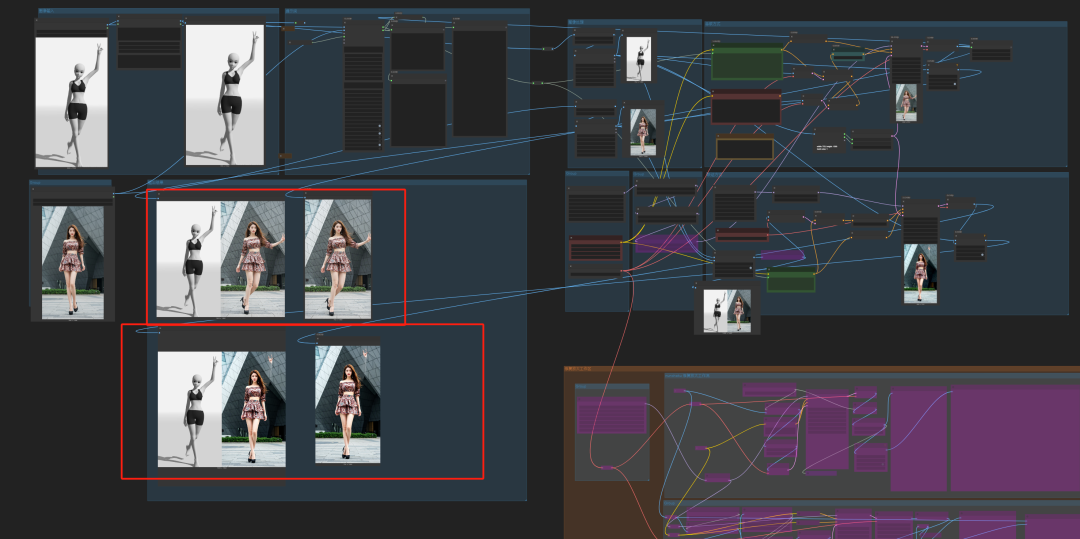
这张图上面是串联方式结果,下面是联结方式结果。明显是上面的优于下面的。
还有,大语言模式分不清左右

左手右手,左脚右脚。

本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
Flux Kontext Dev动嘴P图流体验地址:
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
姿势控制实验的一些结论:
1)flux万物迁移人物姿势迁移效果最好!最稳定最屌!
2)kontext双图预设实现姿势克隆有很好效果。
3)加上controlnet 条件合并、条件平均匀等也是可行的。
但kontext在控制姿势编辑生成方面还是要抽卡,也不能完全百分百。我见红迪上也有大佬训练LORA去解决精准控制,但成功率也就10%。嗯,是个不错的尝试。
以下是我开发的节点,配合kontext能高效出片:
1、comfyUI kontext 标注助手节点:
http://closerai.douyoubuy.cn/2025/07/01/2089/
2、comfyUI kontext提示词生成器节点:
http://aigc.douyoubuy.cn/2025/06/30/2062/
3、closerAI 图像循环助手节点:
http://aigc.douyoubuy.cn/2025/07/05/2137/
comfyUI kontext提示词生成器网页应用:
http://aigc.douyoubuy.cn/closerai-flux-kontext/
以上是closerAI团队制作的stable diffusion comfyUI closerAI开发的节点以及
closerAI kontext 姿势控制工作流介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)